①. jieba分词
使用jieba分词工具,对马蜂窝爬取数据进行简单处理
首先,去除停用词、表情符号,英文等字符,避免干扰
PS:只保留中文字符(if word >= u’\u4e00’ and word <= u’\u9fa5’:)(此数据采用中文’utf-8’编码)
去除停用词(if word not in stopwords:)(stopwords为预加载的中文停用词表)
其次,采用jieba分词的精确分词模式,对预处理过的数据进行分词
最后,将266个景点评论合并到同一个文档中,其中每一行的头部为景点名称,后面为其评论
②. 计算TF-IDF
TF-IDF——词项在向量中的权重方法:表示TF(词频)和IDF(倒文档频率)的乘积:
$tf-idf_{i, j} = tf_{i, j} * idf_i$
其中 TF 表示某个关键词出现的频率,IDF 为所有文档的数目除以包含该词语的文档数目的对数值。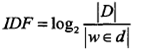
|D|表示所有文档的数目,|w∈d|表示包含词语w的文档数目。
使用 scikit-learn 工具调用CountVectorizer()和TfidfTransformer()函数计算 TF-IDF 值
CountVectorizer():通过 fit_transform 函数将文本中的词语转换为词频矩阵
矩阵元素 weight[i][j] 表示 j 词在第 i 个 文本下的词频,即各个词语出现的次数
通过 get_feature_names() 可看到所有文本的关键字,通过 toarray() 可看到词频矩阵的结果
TfidfTransformer 也有个 fit_transform 函数, 它的作用是计算 tf_idf 值。
输出 93244 维特征,其中共266个景点
故构建的矩阵为:[266][93244]
或许特征值较大,下一步考虑降维
③. K-Means(聚类)
首先,理解一下什么是聚类。
聚类:它的目的也是把数据分类,却与分类不同。事先不知道如何去分,完全是算法自己来判断各条数据之间的相似性,相似的就放在一起。
在聚类的结论出来之前,完全不知道每一类有什么特点,一定要根据聚类的结果通过人的经验来分析,看看聚成的这一类大概有什么特点。
其次,聚类和分类有什么不同。
分类的目标是事先已知的,而聚类则不一样,聚类事先不知道目标变量是什么,类别没有像分类那样被预先定义出来。
最后,重头戏登场。
K-Means:聚类算法有很多种(几十种),K-Means 是聚类算法中的最常用的一种。
特点:简单、好理解、运算速度快
缺点:只能应用于连续型的数据,并且一定要在聚类前手动指定要分成几类。
算法思想:求加权均值,大概需要迭代3~5步
④. 特征提取
1、使用 WordCloud 对特征进行提取,以及生成词云图,由于为旅游景点的游客评价,因此特征提取效果甚是不好,需要融入其它因素
2、使用 tfidf,进行权重计算,但是主要用于聚类,未应用到实际特征提取,需要进一步了解
3、使用 embedding 进行特征提取,需要进一步了解
4、引入评分,做一个新的建模,进行权重加持,需要进一步思考(急)
5、引入历史天气信息,暂时考虑
⑤. 数据清洗
1、抽取爬虫数据时,自动去除非中文、数字、英文(暂时考虑保留)的字符,可以解决数据非正常换行,制表符等转义字符问题,造成字典异常
ps: 地名包含的数字和英文:0123589 M SKY RING O I · ,暂时考虑只保留这些数字和英文,
2、将列表文件转存为字典文件,会自动去重,可以降低数据冗余
3、由于生成字典格式,每写入一个 key-value,均需插入’,’ ,使得最后写出的文件多一个逗号,需手动删除。可以考虑进行优化(已优化,具体测试代码如下:)
import json
list = [{'color': 'greefja放假啊的说法\nnnfhasjkfhajk话费卡技术复核hell', 'point': 5}, {'color': 'yellow', 'point': 10},{'color': 'green\nhell', 'point': 5},{'color': 'green\nhell', 'point': 5}, {'color': 'red', 'point': 15}]
dict = {}
for l in list:
outstr = ''
for g in l['color']: # 数据清洗
if g >= u'\u4e00' and g <= u'\u9fa5': #保留中文字符(utf-8)
outstr += g
elif g >= u'\u0030' and g <= u'\u0039': # 保留阿拉伯数字(utf-8)
g += g
elif g >= u'\u0041' and g <= u'\u007a': # 保留英文大小写(utf-8)
outstr += g
dict[outstr] = str(l['point']) # 生成一个新字典
print(dict)
with open('a.txt', 'w', encoding='utf-8') as c:
c.write(json.dumps(dict, ensure_ascii=False)) 将字典原样写入文件 (其中,ensure_ascii = False 为了保证中文不乱码)
#读取上面保存的文件
with open('a.txt', 'r', encoding='utf-8') as test:
dict = json.loads(test.readline())
print(dict)
⑥. 仿真用户行为日志数据(MongoDB)
1、 json格式数据集导入
向 MongoDB 导入 json 格式的数据集,用 Navicat 15 ,提示 Not a valid JSON。
索性自己使用命令行,向 MongoDB 导入数据集。
sudo mongoimport –db newdb –collection newcoll –file primer-dataset.json
其中,newdb为数据库名字,newcoll为导入的数据集名字
2、清理数据
按条件删除多组mongo数据库中数据:collection.delete_many({条件对})输出删除的总计: result.deleted_count
3、增加天气因素。
字符串截取:将字符串按某一特定字符截取n段,并转为数组。str.split('/', n)
判断字典中是否存在某个key:'xxx' not in dict.keys()
按条件插入或修改多组mongo数据库中的某字段数据:collection.update_many({条件对},{'$set':{修改对}})
4、模拟用户旅游时长
调整 random 概率,预先设置一个集合,则会按该集合各数字所占比列进行random:b = (1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 4, 5, 6, 6, 6)num = random.sample(b, n)
其中n为随机生成的数组长度
5、模拟景区拥挤度
安装插件 chinesecalendar。pip install chinesecalendar
将日期转为 date 型:
保留时分秒:datetime.strptime(date, '%Y-%m-%d') PS: Y, m, d 顺序根据需要进行调整
不保留时分秒:datetime.strptime(date, ‘%Y-%m-%d’).date()
调用插件判断该日期是否为工作日:from chinese_calendar import is_workdayis_workday(date) 返回值为 boolean 类型。
⑧.Mysql
1、 json数据拆分
虽然 MySQL 数据库的查找、更新速度比 MongoDB 快的多(实测情况,MySQL 与 MongoDB 的速度差不太多,最后直接使用 json 文件,进行数据清洗)
但是使用 Python 向其导入 json 文件的速度,相形之下要慢的多,因此需对超大数据集进行拆分
多线程,同步插入数据,更有效率
PS:MySQL 写入,并不会占用 CPU 线程达100%
import json
# 读取大json文件N = []
with open('../data/review.json', 'r', encoding='utf-8') as f1:
for line in f1.readlines():
N.append(line.strip())
print(len(N))
# 转存略显繁琐,但为导入做准备
i = 0
co = 0
f = open ("../data/review_" + str(i) + ".json", 'w', encoding='utf8')
for li in N:
co += 1
f.write(str(li) + '\n')
if co == 600000:
co = 0
i += 1
f.close()
print(str(i) + ' File close!!!')
f = open ("../data/review_" + str(i) + ".json", 'w', encoding='utf8')
continue 2、 json 数据导入
大部分 json 文件不能直接通过 Navicat 导入到 MySQL
- 有一个插件:mysqljsonimport,但是一直没能成功使用, 不知道是 MySQL 版本问题,还是安装时的配置问题,未解决
- 有一个工具,成功导入了 1000 条,但是收费不低,而且破解版一直未找到,记录一下工具名称:JSONtoMySQL。后期可继续寻找
- 通过 python,先将 json 文件读出,然后写入 MySQL,具体代码如下:
import json
import pymysql
conn = pymysql.connect( # 服务器地址
host = '192.168.3.78',
# 端口号
port = 3306,
# 用户名
user = 'root',
# 密码
passwd = '123456',
# 数据库名称
db = 'yelp',
# 字符编码格式
charset = 'utf8',
)
# 设置游标,进行数据库操作
cur = conn.cursor()
# open file
path = '../data/review.json'
with open(path, 'r', encoding='utf-8') as f:
ln = 0
for line in f.readlines():
ln += 1
dic = json.loads(line)
# 一逗号进行key拼接,对应json中的字段
keys = ','.join(dic.keys())
# print(keys)
# 将字典value信息存储成list
valuesList = [dici for dici in dic.values()]
# 进行List列表的遍历
for index1, value1 in enumerate(valuesList):
# 如果是list,将其以str类型存储
if isinstance(value1, list):
valuesList[index1] = str(value1)
# 将str类型转化成元组形式存储
valuesTuple = tuple(valuesList)
# 将value值进行拼接
values = ', '.join(['%s']*len(dic))
# print(values)
# 设置表名称
table="review"
#构造sql插入语句
sql = 'INSERT INTO {table}({keys}) VALUES ({values})'.format(table=table, keys=keys, values=values)
# 执行sql语句
cur.execute(sql,valuesTuple)
conn.commit()
if ln%10000 == 0:
print(str(ln) + ' End!')
conn.close()
⑨. 评价指标
1、NDCG
r=np.array([1,0,0,1,0])
dcg = r[0] + np.sum(r[1:] / np.log2(np.arange(2, r.size + 1)))
r_s = sorted(r,reverse=True)
r_s = np.array(r_s)
dcg_max = r_s[0] + np.sum(r_s[1:] / np.log2(np.arange(2, r_s.size + 1)))
print(dcg,dcg_max)
dcg/dcg_max


