摘要
在本文中,我们提出了一种新的基于强化学习的方法来从大量未标注的政府短文档中提取关键词。引入平均速率正则化,作为模型损失函数的稀疏约束,引导策略网络保留重要词汇。对实验结果的分析表明,该模型在处理大量未标注的政府公文标题时,优于传统的无监督关键词提取方法。
引文
随着中国大数据应用的发展,政府公文数字化在政府相关领域日益普遍。特别是,从用户输入的短文本中提取重要信息是计算机理解和匹配这些短文本的关键步骤。然而,大多数政府文件都没有正确地贴上标签,因此可能无法通过有监督的学习方法从政府文件中提取重要信息。因此,本文引入了适用于处理大型无标记数据集的无监督学习方法来解决这些问题。
一种最流行的无监督关键词提取方法是术语频率倒置文档频率(TFIDF)。尽管TFIDF在很多领域都很流行,但它不能捕获语义。另一种流行的无监督学习方法是延迟狄利克雷分配(LDA)。在L D A中,每个文档都可以看作是各种主题的混合体。然而,当信息量很小时,LDA也可能表现不佳,特别是对于较短的文本。基于图形的方法,如TextRank,也被认为是信息抽取领域的热门方法。TextRank本质上是一种基于递归地从整个图中提取的全局信息来确定Word重要性的方法。然而,对于简短的文本,构建的“图”有时过于简单,无法评估单词的重要性。因此,对于较短的政府文档,传统的无监督关键词提取模型如TF-IDF、LDA和基于图的TextRank等都存在局限性。
近年来,深度学习算法极大地加速了人工智能在自然语言处理(NLP)领域的发展。特别是,递归神经网络(RNN)、长短期记忆(LSTM)及其变种门式递归单元(GRU)可以有效地从原始文档中提取文本特征。例如,中可以通过序列标注来提取关键词,但这种方法属于有监督学习的范畴,不适合于大型的未标注文本数据集。另一方面,强化学习现已被应用于信息抽取任务,基于强化学习的结构化表示也被引入文本分类。但是上述模型需要大量的文本分类标签,这使得我们很难将这种结构化的表示方法应用到标签较少的政府文档上。受这些方法的启发,我们提出了一种基于强化学习的关键字抽取方法,该方法主要针对较短的政府文档。该方法不需要大的标注数据集,能够自适应地从特定主题的短文本中提取关键词。这种方法也可以作为文本匹配、文本检索和信息提取等进一步任务的基础。
模型
模型架构
我们提出的基于强化学习的关键词抽取模型由三部分组成:1)策略网络:策略网络通过强化学习算法学习单词的取舍策略。2)特征表示和匹配:通过嵌入每个被接受的词来获得文本的语义特征向量。然后计算输入文本和候选文本之间的相似度,得到基于相似度的候选文本排序列表。3)奖励反馈:根据奖励函数和候选文本排序列表,获取奖励并反馈给策略网络。
策略网络
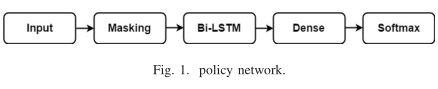
策略网络用于学习有用的策略,以确定文本中的单词是否重要。这一过程可以看作是一项序列标记任务。我们引入了 Bi-LSTM 神经网络来构建这样的策略网络,如图1所示。在该网络中,输入层用于接受经过预处理的短文本序列。输入层的最大时间步长设置为30,每个时间步长对应的词嵌入向量的维数设置为300。考虑到我们的大多数短文本都有不同的长度,我们通过 Masking Layer 来掩蔽多余的时间步长。此外,我们还采用了 Bi-LSTM,其单元数设置为64,用于提取文本的序列特征。然后引入具有64个单元的致密层来结合这些序列特征,并且每个单元通过一个 tanh 激活函数。最后,通过 Softmax layer 得到了策略网络的可能分布。动作空间的大小为2。
在此基础上,设计了策略网络的损失函数。损失函数 Loss 由两部分组成:第一部分根据相应的 $R_{i}$ 赋予较高奖励更大的权重。这一部分的损失函数由$Loss_{1}$表示。损失函数的第二部分由$Loss_{2}$表示,通过将单词被选择的可能性的平均值限制为 $\gamma$ 来指导策略网络选择单词。损失函数的两个部分的定义如公式(1)所示。
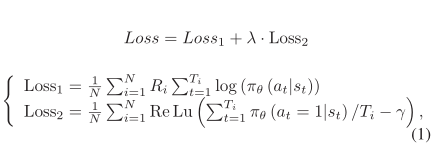
其中,超参数 $\lambda$ 是权重系数,N代表样本总数,$T_{i}$ 是文本 $i^{th}$ 的长度,$R_{i}$ 是文本 $i^{th}$ 获得的回馈奖励,$\pi_{\Theta}(a_t| s_t)$ 表示在 t 时刻的状态 $s_t$ 下,选择 $a_t$ 的条件概率,特别的 $\pi_{\Theta}(a_t = 1| s_t)$ 表示在 t 时刻,状态为 $s_t$ 的状态下,当前词被选为关键词的概率,ReLu(x) 是线性整流函数,当 $x > 0$ 是输出想, 否则输出0,参数$\gamma$ 表示一个词预期被选中的可能性。
特征表示与匹配
经过策略网络选择后,需要将关键词转换为特征向量。我们引入了有较大的预训练的嵌入模型 Word2Vec 来获得每个提取关键词的语义特征向量。然后,通过对所有对应关键字的特征向量求平均来获得文本表示。利用短文本对应的特征向量之间的余弦距离来计算短文本之间的相似度。然后,我们可以通过选择相似度最高的候选文本来获得当前短文本最相似的候选文本。
回馈奖励
策略网络需要奖励信号才能知道其学习的关键词提取策略是否足够好。我们注意到,如果策略网络提取的关键词包含短文本的要点,则可以从候选文本中找到相似度较高的短文本。因此,奖励信号是根据短文本与相应候选人之间的相似度列表来设计的。假设在策略网络的每一批训练中,需要匹配的候选集被标注为 C,那么候选集的数量就是 C 的大小,可以表示为 |C|(|C|>10)。为了获得短文本与候选文本之间的排序相似度的对应列表,需要根据计算出的相似度将每个样本与候选集中的每个文本进行匹配。假设 x 为 $t_i$ 的推荐等级,即样本 $d_i$ 的对应标签,则奖励金额计算如下:
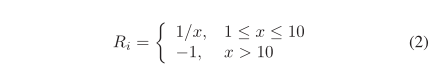
然后,这种奖励 $R_i$ 被反馈到损失函数中,如公式 (1),用来训练策略网络。
实验和结果
实验数据
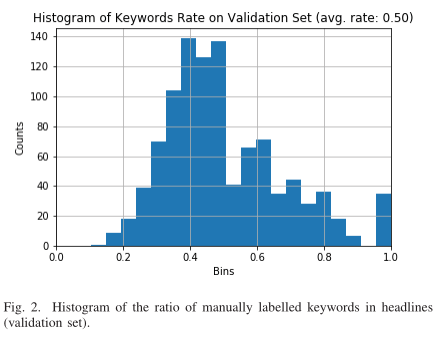
为了训练这个模型,我们爬行了大量的政府文档,并提取了每个文档的标题。爬行的文本涵盖了农业、文化、旅游、扶贫和其他政府事务的主题。爬行的标题分为训练集、验证集和测试集,分别有12925个样本、1,024个样本和2,048个样本。为了自动生成标题相关对,我们首先计算训练集中所有标题对之间的Rouge分数,其中Rouge分数被设置为Rouge-1和Rouge-2分数的平均值。对于每个标题,它都会将 Rouge 得分最高的标题配对。但是,我们不会在验证和测试集中生成标题对。为了选择超参数并量化所提出的模型的性能,我们在验证和测试集中手动选择并标注了所有标题关键词。我们首先对标题进行预处理,排除所有数字和英文部分,但仍保留停用词。然后,我们利用开源的 jieba 库对所有预处理后的标题进行标记化。通过预先训练好的词嵌入模型,将每个时间步对应的词嵌入到300维的特征向量中,作为策略网络的输入。我们计算并绘制了验证集标签标题中关键词的比例直方图,如图2所示,标题中关键词的平均比例为0.5。因此,为了使策略网络排除无关或不重要的信息,我们将等式(1)中的超参数 $\gamma$ 设置为0.5。
结果分析
我们在测试集上对该模型和其他传统的非监督方法如TF-IDF、LDA和TextRank的性能进行了评估。从图2中我们注意到,验证集中每个标题中关键字的平均比率为0.5,因此上述传统方法提取的关键字数量被设置为标记化标题中所有单词的一半大小。此外,通用硬件环境包括:1) CPU: Intel® Core™ i5-7500 @3.4GHz. 2) RAM: 8GB.
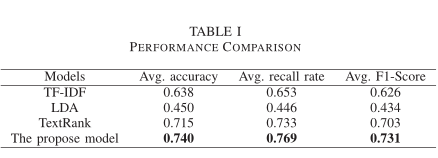
从表I可以看出,采用平均速率正则化的模型在所有评价指标上都优于TF-IDF、LDA和TextRank等传统方法。该模型的平均准确率达到0.740,平均召回率达到0.769,平均F1得分达到0.731。总的来说,该模型对于从大型无标签政府文档的标题中提取关键词是可行的,该方法为政府文档数字化领域提供了一种新的思路。
结论
本文提出了一种利用强化学习从大量未标注的政府短文档中提取关键词的模型。为了引导策略网络保留重要词汇,引入平均速率正则化作为模型损失函数的稀疏约束。该模型的平均准确率达到0.740,平均召回率达到0.769,平均F1得分达到0.731。通过对实验结果的分析,我们得出结论:该模型在政府文档标题关键词提取方面的性能优于传统的无监督方法。提取的关键词还可以进一步应用于文本匹配、文本检索和信息提取等任务。



